在人工智能技术蓬勃发展的今天,语音识别已成为提升工作效率与生活便利的核心工具之一。作为OpenAI推出的开源语音识别模型,Whisper凭借其高精度、多语言支持和本地化运行的特点,成为开发者与普通用户的首选工具。本文将从安全下载、安装配置到实际应用,提供一站式指南,助你快速掌握这一技术利器。
一、Whisper的核心优势
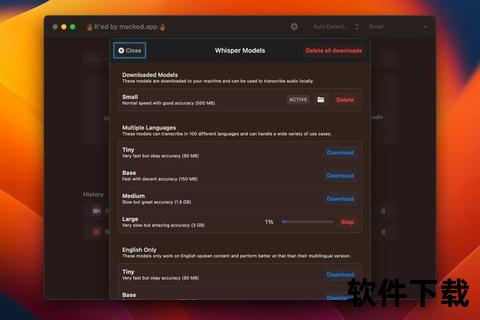
1. 高精度与多语言支持
Whisper基于68万小时的语音数据训练,支持99种语言,尤其对英语、中文等主流语言的识别准确率接近人类水平。其模型分为5种规模(tiny至large),用户可根据硬件条件灵活选择。
2. 本地化运行保障隐私
与依赖云服务的商业产品不同,Whisper完全在本地运行,避免敏感数据外泄,尤其适合处理会议录音、个人语音备忘录等隐私内容。
3. 灵活的应用场景
从视频字幕生成、会议记录整理到司法取证,Whisper可通过参数调整适应不同需求。例如,通过`--task translate`实现语音翻译,或通过`--return_timestamps`生成时间戳。
二、安全下载与安装指南
步骤1:环境准备
bash
CPU版本
pip install torch torchvision torchaudio
GPU版本(需CUDA)
pip install torch torchvision torchaudio --extra-index-url
步骤2:安装Whisper
通过pip直接安装最新版:
bash
pip install openai-whisper
若网络不稳定,可使用国内镜像源加速:
bash
pip install openai-whisper -i
步骤3:模型下载
默认情况下,首次运行时会自动下载模型(存储于`~/.cache/whisper`)。也可手动从[Hugging Face]下载`.pt`文件并指定路径。
三、从入门到精通:使用教程
基础功能:语音转文字
python
import whisper
model = whisper.load_model("base") 选择base模型
result = model.transcribe("audio.mp3", language="chinese")
print(result["text"])
此代码将音频转换为中文文本,适用于快速转录会议记录或视频字幕。
高阶功能:参数优化
常见问题解决
四、安全性与隐私保护
1. 数据本地化:所有处理均在用户设备完成,避免云端传输风险。
2. 开源透明:Whisper代码与模型权重完全公开,社区可审查代码安全性。
3. 自定义模型路径:通过环境变量`WHISPER_MODEL_DIR`指定存储位置,防止敏感数据泄露。
五、用户评价与未来展望
用户反馈
未来发展方向
Whisper不仅是技术爱好者的实验工具,更已逐步渗透至企业办公、教育、医疗等领域。通过本文指南,用户可安全高效地完成从下载到部署的全流程,解锁语音识别的无限潜力。随着开源社区的持续贡献,Whisper有望在自动化与隐私保护的平衡中开辟更广阔的应用场景。
